����.: Что дальше ����: Кластеризация + виртуализация : ����.: Строим первый виртуальный сервер ����������
В большинстве случаев на одном физическом сервере размещают несколько виртуальных серверов, при этом необходимо каким-то образом обеспечить доступность сервисов, работающих на виртуальных серверах, другим физическим машинам. Пробрасывать каждому виртуальному серверу по физическому интерфейсу накладно, да и неудобно. Часто хочется спрятать все виртуальные сервера за одним маршрутизатором/брандмауэром.
Посмотрим, какие средства для этого предлагает OpenVZ. Он предлагает 2 типа виртуальных сетевых интерфейсов:
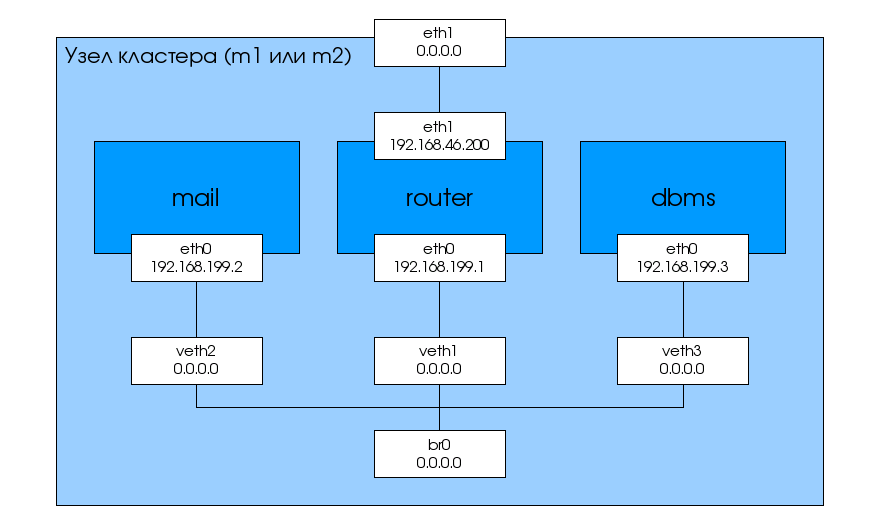
Если в качестве маршрутизатора/брандмауэра для доступа к виртуальным серверам использовать физический сервер, стоит, несомненно, предпочесть venet. Поскольку такая конфигурация более распространена, то и venet-интерфейсы используются чаще. Однако чем сложнее конфигурация маршрутизатора/брандмауэра, тем больше оснований появляется для вынесения его в отдельный виртуальный сервер, чтобы не перегружать физический сервер лишними задачами и лишним ПО. В нашем случае дополнительным поводом стало желание иметь один и тот же адрес виртуального сервера, доступный извне, независимо от адреса узла кластера, на котором он в данный момент работает. Эта конфигурация в некоторых случаях может оказаться еще более сложной, если, например, на проброшенном физическом интерфейсе организовать поддержку IEEE 802.1Q VLAN, чтобы принять несколько vlan-ов, но с точки зрения настройки OpenVZ эта конфигурация не будет ничем отличаться от того, что было рассмотрено выше "-- разница будет только в настройке проброшенного сетевого интерфейса. Более важным является то, что в случае использования в качестве маршрутизатора/брандмауэра виртуального сервера более удобным будет построить виртуальную сеть на veth-интерфейсах. Выглядеть это будет так, как показано на рисунке 3.
Итак, для каждого виртуального сервера мы создаем veth-интерфейс, а концы этих интерфейсов со стороны физического сервера объединяем в бридж "-- в результате получается аналог хаба, в который включены все виртуальные сервера. Один из них уже имеет проброшенный в него физический интерфейс "-- этот виртуальный сервер и будет играть роль маршрутизатора/брандмауэра.
Создаем и стартуем виртуальные сервера:
[root@m1 ~]# vzctl create 102 --ostemplate altlinux-sisyphus --config vps.basic Creating VE private area: /var/lib/vz/private/102 Performing postcreate actions VE private area was created [root@m1 ~]# vzctl set 102 --name mail --save Name ve1 assigned Saved parameters for VE 102 [root@m1 ~]# vzctl set mail --onboot yes --save Saved parameters for VE 102 [root@m1 ~]# vzctl set mail --hostname mail.mydomain.com --save Saved parameters for VE 102 [root@m1 ~]# vzctl start mail Starting VE ... VE is mounted Adding IP address(es): 192.168.199.2 Setting CPU units: 1000 Set hostname: mail.mydomain.com VE start in progress... [root@m1 ~]# vzctl create 103 --ostemplate altlinux-sisyphus --config vps.basic Creating VE private area: /var/lib/vz/private/103 Performing postcreate actions VE private area was created [root@m1 ~]# vzctl set 103 --name dbms --save Name ve2 assigned Saved parameters for VE 103 [root@m1 ~]# vzctl set dbms --onboot yes --save Saved parameters for VE 103 [root@m1 ~]# vzctl set dbms --hostname dbms.mydomain.com --save Saved parameters for VE 103 [root@m1 ~]# vzctl start dbms Starting VE ... VE is mounted Adding IP address(es): 192.168.199.3 Setting CPU units: 1000 Set hostname: dbms.mydomain.com VE start in progress...
Создаем и конфигурируем veth-интерфейсы внутри виртуальных серверов:
[root@m1 ~]# vzctl set router --veth_add veth1,00:12:34:56:78:9A,eth0,00:12:34:56:78:9B --save Processing veth devices Saved parameters for VE 101 [root@m1 ~]# vzctl exec router ip address add 192.168.199.1/24 dev eth0 [root@m1 ~]# vzctl exec router ip link set eth0 up [root@m1 ~]# vzctl set mail --veth_add veth2,00:12:34:56:78:9C,eth0,00:12:34:56:78:9D --save Processing veth devices Saved parameters for VE 102 [root@m1 ~]# vzctl exec mail ip address add 192.168.199.2/24 dev eth0 [root@m1 ~]# vzctl exec mail ip link set eth0 up [root@m1 ~]# vzctl set dbms --veth_add veth3,00:12:34:56:78:9E,eth0,00:12:34:56:78:9F --save Processing veth devices Saved parameters for VE 103 [root@m1 ~]# vzctl exec dbms ip address add 192.168.199.3/24 dev eth0 [root@m1 ~]# vzctl exec dbms ip link set eth0 up
Имена интерфейсов и их MAC-адреса мы придумываем сами, поэтому необходимо, чтобы последние не пересекались с существующими.
Объединяем концы veth-интерфейсов со стороны физического сервера в бридж:
[root@m1 ~]# ip link set veth1 up [root@m1 ~]# ip link set veth2 up [root@m1 ~]# ip link set veth3 up [root@m1 ~]# brctl addbr br0 [root@m1 ~]# brctl addif br0 veth1 [root@m1 ~]# brctl addif br0 veth2 [root@m1 ~]# brctl addif br0 veth3 [root@m1 ~]# ip link set br0 up
Проверяем работоспособность внутренней виртуальной сети:
[root@m1 ~]# vzctl exec router ping 192.168.199.2 PING 192.168.199.2 (192.168.199.2) 56(84) bytes of data. 64 bytes from 192.168.199.2: icmp_seq=1 ttl=64 time=15.9 ms [root@m1 ~]# vzctl exec router ping 192.168.199.3 PING 192.168.199.3 (192.168.199.3) 56(84) bytes of data. 64 bytes from 192.168.199.3: icmp_seq=1 ttl=64 time=3.71 ms
Теперь на виртуальных серверах описываем маршрут во внешнюю физическую сеть:
[root@m1 ~]# vzctl exec mail ip route add 192.168.0.0/16 via 192.168.199.1 [root@m1 ~]# vzctl exec dbms ip route add 192.168.0.0/16 via 192.168.199.1
На виртуальном маршрутизаторе включаем пересылку пакетов между физической и виртуальной сетями:
[root@m1 ~]# vzctl exec router sysctl -w net.ipv4.ip_forward=1
Теперь если на машине из физической сети 192.168.46.0/24 описать маршрут в сеть 192.168.199.0/24 (или настроить NAT на виртуальном маршрутизаторе), мы получим то, чего и добивались:
[root@m1 ~]# vzctl exec mail ping 192.168.46.1 PING 192.168.46.1 (192.168.46.1) 56(84) bytes of data. 64 bytes from 192.168.46.1: icmp_seq=1 ttl=63 time=0.982 ms
Желательно, чтобы все описанные выше настройки сохранялись при перезапуске виртуальных серверов, сервиса vz и ведущего узла кластера. С настройками виртуальных серверов проще всего "-- их можно сохранить в etcnet:
[root@m1 ~]# vzctl enter mail [root@mail /]# mkdir /etc/net/ifaces/eth0 [root@mail /]# echo 192.168.199.2/24 > /etc/net/ifaces/eth0/ipv4address [root@mail /]# echo 192.168.0.0/16 via 192.168.199.1 dev eth0 > /etc/net/ifaces/eth0/ipv4route [root@mail /]# echo "BOOTPROTO=static > ONBOOT=yes > TYPE=eth" > /etc/net/ifaces/eth0/options [root@m1 ~]# vzctl enter dbms [root@dbms /]# mkdir /etc/net/ifaces/eth0 [root@dbms /]# echo 192.168.199.3/24 > /etc/net/ifaces/eth0/ipv4address [root@dbms /]# echo 192.168.0.0/16 via 192.168.199.1 dev eth0 > /etc/net/ifaces/eth0/ipv4route [root@dbms /]# echo "BOOTPROTO=static > ONBOOT=yes > TYPE=eth" > /etc/net/ifaces/eth0/options
Для автоматического добавления конца veth-интерфейсов со стороны физического сервера в бридж при старте соответствующего виртуального сервера потребуется исправить скрипт /usr/sbin/vznetcfg, добавив в конец функции init_veth() строку (сделать это нужно на двух узлах кластера):
brctl addif br0 ${dev}
В будущем разработчики OpenVZ обещают доработать этот скрипт, чтобы подобного рода измения можно было описывать в конфигурационном файле.
Наконец, бридж тоже нужно создать, и сделать это необходимо еще до старта всех виртуальных серверов. Лучше всего добавить его создание в конфигурацию etcnet на обеих узлах кластера:
[root@m1 ~]# mkdir /etc/net/ifaces/br0 [root@m1 ~]# echo TYPE=bri > /etc/net/ifaces/br0/options
Есть одна неприятная деталь. В конфигурацию виртуальных серверов мы добавили маршрут в сеть 192.168.0.0/16, но во многих случаях нам потребуется добавить туда маршрут по уполчанию. Сделать этого мы не сможем, так как такой маршрут, созданный OpenVZ заранее для собственных нужд, уже есть:
[root@m1 ~]# vzctl exec mail ip route 192.168.199.0/24 dev eth0 proto kernel scope link src 192.168.199.2 192.0.2.0/24 dev venet0 scope host 192.168.0.0/16 via 192.168.199.1 dev eth0 default via 192.0.2.1 dev venet0
Он создается и автоматически привязывается к интерфейсу venet0. Ни эта довольно навязчивая автоматика, ни venet-интерфейсы вообще нам сейчас не нужны, мы используем только veth. Поэтому чтобы такого не происходило, потребуется исправить скрипт, выполняющий настройку сетевых интерфейсов виртуального сервера. В случае ALT Linux Sisyphus это /etc/vz/dists/scripts/etcnet-add_ip.sh. В нем нам нужно модифицировать функцию add_ip() таким образом, чтобы она выполнялась только при наличии присвоенного venet-интерфейсу адреса:
add_ip()
{
local i ip
if [ -n "$IP_ADDR" ]; then
if [ "$VE_STATE" = "starting" ]; then
setup_network
fi
backup_configs "$IPDELALL"
i=0
for ip in ${IP_ADDR}; do
i="$(find_unused_alias "$((i+1))")"
create_alias "$ip" "$i"
done
move_configs
if [ "$VE_STATE" = "running" ]; then
# synchronyze config files & interfaces
ifdown "$VENET_DEV"
ifup "$VENET_DEV"
fi
fi
}
Затем в виртуальных серверах необходимо удалить из etcnet настройки интерфейса venet0:
[root@m1 ~]# vzctl exec router rm -rf /etc/net/ifaces/venet0 [root@m1 ~]# vzctl exec mail rm -rf /etc/net/ifaces/venet0 [root@m1 ~]# vzctl exec dbms rm -rf /etc/net/ifaces/venet0
Теперь можно перезапустить сервис vz "-- в конфигурации виртуальных серверов останутся только те маршруты, которые мы указали явно.
Таким образом мы добились того, чего хотели: в штатном режиме виртуальные сервера mail и dbms работают на узле m1, а в случае его отказа автоматически переезжают на узел m2, при этом с точки зрения внешнего наблюдателя из физической сети 192.168.46.0/24 наблюдается лишь кратковременный перерыв в обслуживании:
$ ping 192.168.199.2 PING 192.168.199.2 (192.168.199.2) 56(84) bytes of data. 64 bytes from 192.168.199.2: icmp_seq=1 ttl=64 time=0.549 ms ... From 192.168.46.1 icmp_seq=83 Destination Host Unreachable ... From 192.168.46.200 icmp_seq=83 Destination Host Unreachable ... 64 bytes from 192.168.199.2: icmp_seq=179 ttl=64 time=1.05 ms --- 192.168.46.200 ping statistics --- 179 packets transmitted, 25 received, +93 errors, 86% packet loss, time 178149ms rtt min/avg/max/mdev = 0.298/193.970/1702.783/397.285 ms, pipe 3